
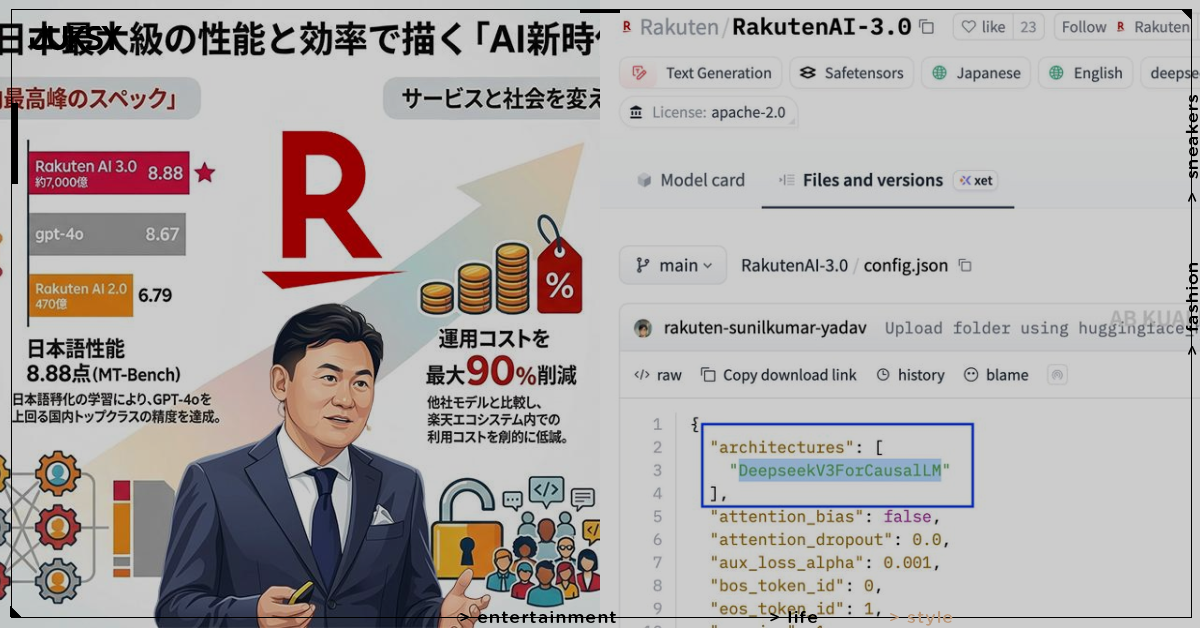
樂天集團(Rakuten)日前高調發布旗下最新大型語言模型「Rakuten AI 3.0」,對外宣稱這是「日本國內最大規模、高效能的日語專用AI模型」,並以免費開源的方式釋出,訊息一出引發科技圈廣泛追蹤。然而,就在發布後短短數小時內,社群上的開發者便在 HuggingFace 平台翻出模型的設定檔,發現其架構竟與中國AI公司深度求索(DeepSeek)的 DeepSeek V3 高度吻合,讓這場「日本之光」的發布會瞬間變調。
自研旗艦遭翻底細,DeepSeek V3 架構曝光
根據樂天官方說明,Rakuten AI 3.0 採用混合專家架構(Mixture of Experts,MoE),總引數量高達約 6710 億,每次推理時啟動約 370 億引數,並在多項日語基準測試中取得優異成績。樂天強調,這款模型是作為日本經濟產業省主導的「GENIAC計畫」(Generative AI Accelerator Challenge)一環所開發,旨在強化日本國內生成式AI的自主研發能力,並以 Apache 2.0 授權條款免費開源,供全球開發者使用。GENIAC計畫由日本經濟產業省於2024年2月啟動,目標是扶植國內基礎模型開發實力,樂天此次參與正是該計畫的重要成果之一。不過,社群開發者在仔細檢視 HuggingFace 上的模型設定檔後,發現其架構引數與 DeepSeek V3 的公開資料幾乎完全一致,包括模型層數、隱藏層維度等核心設計,讓外界對「自主研發」的說法打上大大的問號。訊息在 X(前身為 Twitter)平台上迅速擴散,不少日本科技業人士轉寄討論,直指樂天的宣傳方式有誇大之嫌。
DeepSeek V3 是由中國杭州深度求索公司開發的開源大型語言模型,以低成本、高效能著稱,在全球AI圈引發廣泛追蹤。由於 DeepSeek 採用開源授權,任何公司在技術上確實可以基於其架構進行二次開發或微調,這在AI產業並非罕見做法。然而,樂天在對外宣傳時強調「自研」與「日本最大」,卻未主動揭露底層架構來源,才讓這次發布引發強烈反彈。值得注意的是,台灣行政院已宣布公務機關全面停用 DeepSeek 相關服務,理由是資安與個資外洩疑慮,此背景讓樂天此次事件在亞洲科技圈更加敏感。目前樂天方面尚未就「是否基於 DeepSeek V3」一事作出正面回應,但相關討論已在日本與國際科技社群持續延燒。
Rakuten AI 3.0 的模型已上架 HuggingFace 供外界下載,技術社群的逐行比對仍在進行中,更多架構細節預計將陸續浮出水面。這場「日本最大AI」的爭議,也再次點燃外界對AI模型透明度與開發溯源的討論熱度。

本站圖片部分取自於網路,如有版權使用疑慮煩請告知。
-
 樂天桃猿今(6)日宣布補進兩名外籍野手,分別為 31 歲的 Ronnie Dawson(道威聖)與 34 歲的 Adam Walker(威克),希望藉由兩位長打好手加盟,全面提升球隊下半季進攻火力,全力爭取季後賽門票與總冠軍。球團表示,這項 ...2026-07-06
樂天桃猿今(6)日宣布補進兩名外籍野手,分別為 31 歲的 Ronnie Dawson(道威聖)與 34 歲的 Adam Walker(威克),希望藉由兩位長打好手加盟,全面提升球隊下半季進攻火力,全力爭取季後賽門票與總冠軍。球團表示,這項 ...2026-07-06 -
 日本職棒投下一顆震撼彈!根據日媒《週刊實話WEB》報導,東北樂天金鷲球團疑似正進入出售的最終調整階段,轉讓金額高達300億日圓,買家鎖定日本網路巨頭賽博代理商(CyberAgent)的董事長藤田晉。消息一出,立刻在日本棒球界掀起軒然大波,球 ...2026-07-01
日本職棒投下一顆震撼彈!根據日媒《週刊實話WEB》報導,東北樂天金鷲球團疑似正進入出售的最終調整階段,轉讓金額高達300億日圓,買家鎖定日本網路巨頭賽博代理商(CyberAgent)的董事長藤田晉。消息一出,立刻在日本棒球界掀起軒然大波,球 ...2026-07-01 -
 金州勇士這個夏天同時在商業與球隊戰力兩條線上大動作出擊。球衣廣告方面,合作長達9年的日本電商巨頭樂天(Rakuten)正式出局,由澳洲AI雲端服務商Iren接棒,年度合約金額高達5000萬美元,一舉寫下北美職業運動史上最高贊助紀錄。與此同時 ...2026-06-29
金州勇士這個夏天同時在商業與球隊戰力兩條線上大動作出擊。球衣廣告方面,合作長達9年的日本電商巨頭樂天(Rakuten)正式出局,由澳洲AI雲端服務商Iren接棒,年度合約金額高達5000萬美元,一舉寫下北美職業運動史上最高贊助紀錄。與此同時 ...2026-06-29 -
 樂天桃猿無預警宣布補進洋砲,讓不少棒球迷又驚又喜。球隊官方 Instagram 近日正式宣布,前韓職起亞英雄隊外野手 Ronnie Dawson 將加盟桃猿,成為本季中華職棒第 3 位洋砲。消息曝光後,立即在網路上掀起熱烈討論,不少球迷直呼 ...2026-06-24
樂天桃猿無預警宣布補進洋砲,讓不少棒球迷又驚又喜。球隊官方 Instagram 近日正式宣布,前韓職起亞英雄隊外野手 Ronnie Dawson 將加盟桃猿,成為本季中華職棒第 3 位洋砲。消息曝光後,立即在網路上掀起熱烈討論,不少球迷直呼 ...2026-06-24 -
 中職樂天桃猿二軍游擊手游承勳,近日捲入場外感情風波。一名女攝影師在社群平台 Threads 發文,爆料自己曾與某位樂天球員交往,對方在交往期間謊話連篇,甚至在今年2月赴日本石垣島參加交流賽期間,帶陪酒女郎回飯店過夜,並聲稱手邊握有照片為證。 ...2026-05-22
中職樂天桃猿二軍游擊手游承勳,近日捲入場外感情風波。一名女攝影師在社群平台 Threads 發文,爆料自己曾與某位樂天球員交往,對方在交往期間謊話連篇,甚至在今年2月赴日本石垣島參加交流賽期間,帶陪酒女郎回飯店過夜,並聲稱手邊握有照片為證。 ...2026-05-22 -
 中職樂天桃猿二軍游擊手游承勳,近日遭一名女攝影師在社群平台 Threads 發文影射劈腿。爆料內容指控某位樂天球員在交往期間謊話連篇,甚至在今年2月赴日本石垣島參加交流賽期間,帶陪酒女郎回飯店過夜,並聲稱「甚至還有照片」。貼文曝光後迅速在網 ...2026-05-22
中職樂天桃猿二軍游擊手游承勳,近日遭一名女攝影師在社群平台 Threads 發文影射劈腿。爆料內容指控某位樂天球員在交往期間謊話連篇,甚至在今年2月赴日本石垣島參加交流賽期間,帶陪酒女郎回飯店過夜,並聲稱「甚至還有照片」。貼文曝光後迅速在網 ...2026-05-22 -
 樂天桃猿啦啦隊 Rakuten Girls成員高橋佳帆(KAHO),以清新甜美的形象加盟後迅速累積高人氣,備受球迷關注。近日她更宣布進軍日本寫真雜誌,以床邊比基尼造型亮相,大方展現不同於以往的性感魅力,成功掀起話題。 ...2026-05-06 更新
樂天桃猿啦啦隊 Rakuten Girls成員高橋佳帆(KAHO),以清新甜美的形象加盟後迅速累積高人氣,備受球迷關注。近日她更宣布進軍日本寫真雜誌,以床邊比基尼造型亮相,大方展現不同於以往的性感魅力,成功掀起話題。 ...2026-05-06 更新 -
 中華職棒再傳球員酒駕爭議,樂天桃猿投手李育朋日前爆出無照酒駕肇事,球團在得知消息後迅速做出處置,正式宣布終止合約。消息曝光後立刻在棒球圈掀起高度關注,也讓外界再次聚焦職業球員的紀律與品行管理問題。 ...2026-04-23
中華職棒再傳球員酒駕爭議,樂天桃猿投手李育朋日前爆出無照酒駕肇事,球團在得知消息後迅速做出處置,正式宣布終止合約。消息曝光後立刻在棒球圈掀起高度關注,也讓外界再次聚焦職業球員的紀律與品行管理問題。 ...2026-04-23 -
 衛冕冠軍樂天桃猿本季開局在進攻端表現不如預期。根據中職官方數據,球隊前 12 場比賽合計僅攻下 29 分,場均得分僅 2.42 分,其中更有 7 場比賽得分壓在 2 分以下,整體火力明顯不足。 ...2026-04-17
衛冕冠軍樂天桃猿本季開局在進攻端表現不如預期。根據中職官方數據,球隊前 12 場比賽合計僅攻下 29 分,場均得分僅 2.42 分,其中更有 7 場比賽得分壓在 2 分以下,整體火力明顯不足。 ...2026-04-17 -
 樂天啦啦隊迎來 河智媛、廉世彬、禹洙漢、高佳彬 與 金佳垠 組成「韓籍五本柱」,話題性持續延燒。日前新賽季首度合體熱舞,其中禹洙漢的個人片段更在網路上掀起瘋傳,火辣魅力瞬間引爆討論! ...2026-04-13
樂天啦啦隊迎來 河智媛、廉世彬、禹洙漢、高佳彬 與 金佳垠 組成「韓籍五本柱」,話題性持續延燒。日前新賽季首度合體熱舞,其中禹洙漢的個人片段更在網路上掀起瘋傳,火辣魅力瞬間引爆討論! ...2026-04-13 -
 樂天桃猿近日推出超狂主題日企劃,讓兩位洋投在賽前換上女僕裝亮相,畫面一曝光立刻在球迷間瘋傳。右投手魔爾曼與麥斯威尼身穿女僕服的照片由球團官方 Threads 帳號發布,兩人截然不同的反應成為全場焦點。 ...2026-04-12
樂天桃猿近日推出超狂主題日企劃,讓兩位洋投在賽前換上女僕裝亮相,畫面一曝光立刻在球迷間瘋傳。右投手魔爾曼與麥斯威尼身穿女僕服的照片由球團官方 Threads 帳號發布,兩人截然不同的反應成為全場焦點。 ...2026-04-12